基准测试
基准测试通过使用Java microbenchmark harness 来提供准确的分析结果。这些缓存将被如下配置,
Caffeine 和 ConcurrentLinkedHashMap根据CPU的数量调整其内部大小。
Guava 并发度被配置为
64(默认情况下为4来减少内存开销)。请注意Guava将会#2063 解决性能问题,但已经被积压多年(提升25倍以上!)。Ehcache v2 内部被硬编码为100段, 而 v3 版本没有进行分段
Infinispan "old" 是一个类似Guava的缓存,并且并发度被配置为
64Infinispan "new"是使用无锁deque(默认版本为 v7.2+)重写的
本地测试环境
运行在 MacBook Pro i7-4870HQ CPU @ 2.50GHz (4 core) 16 GB Yosemite系统。
生成计算
在这个 基准测试 中,缓存是无界且被完全填充的,并且生成计算的结果将返回一个常量。这个基准测试体现了生成计算元素的时候将当前元素加锁产生的开销。如果调用不存在,Caffeine 首先会进行一次无锁的预筛选,在进行原子操作。绘图的场景是所有线程对("sameKey")进行查询,并基于Zipf在各个线程中查询不同的key("spread")。
[[ https://raw.githubusercontent.com/ben-manes/caffeine/master/wiki/throughput/compute.png | height = 400px ]]
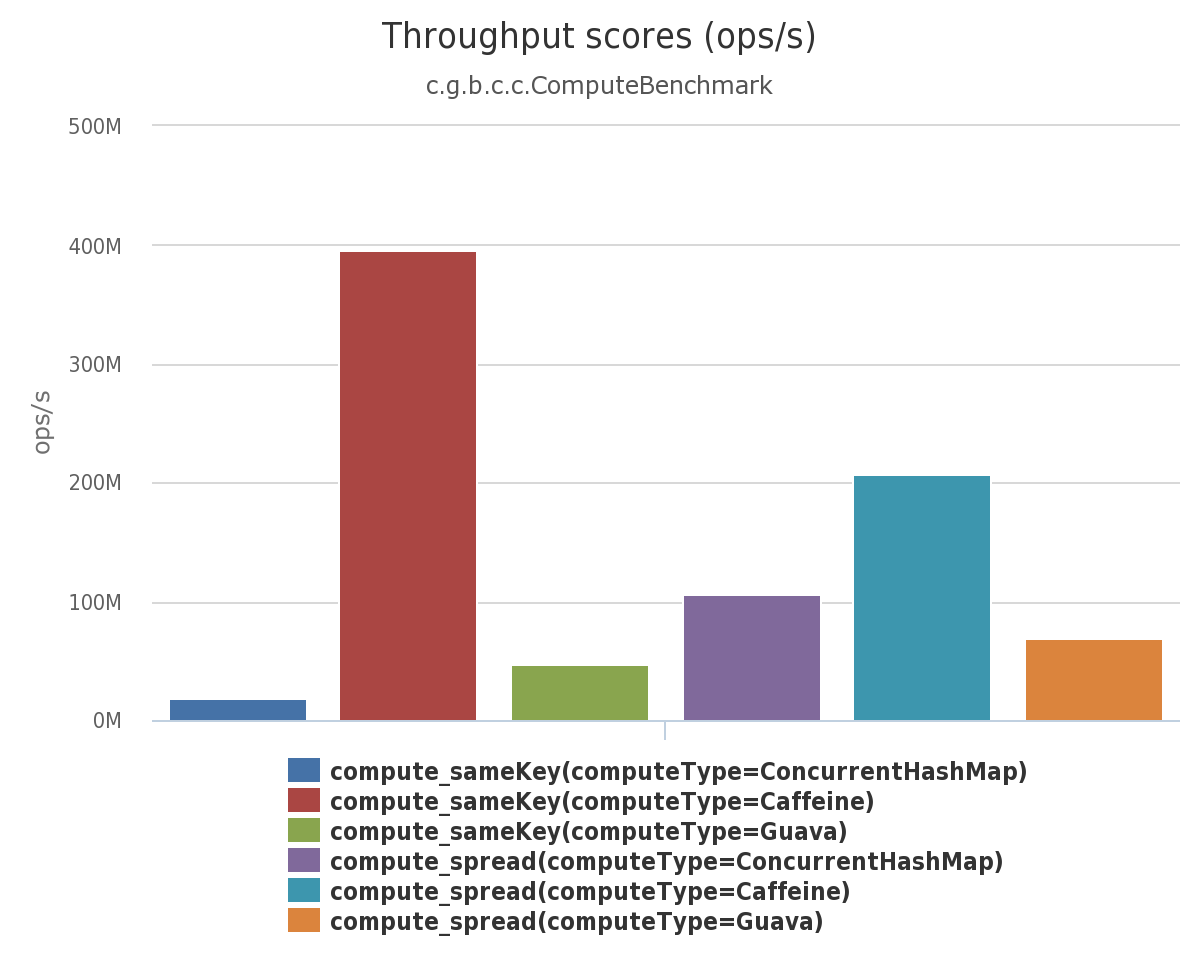{kind=link}
读 (100%)
在这个基准测试中, 8 线程对一个配置了最大容量的缓存进行并发读。
[[ https://raw.githubusercontent.com/ben-manes/caffeine/master/wiki/throughput/read.png | height = 400px ]]
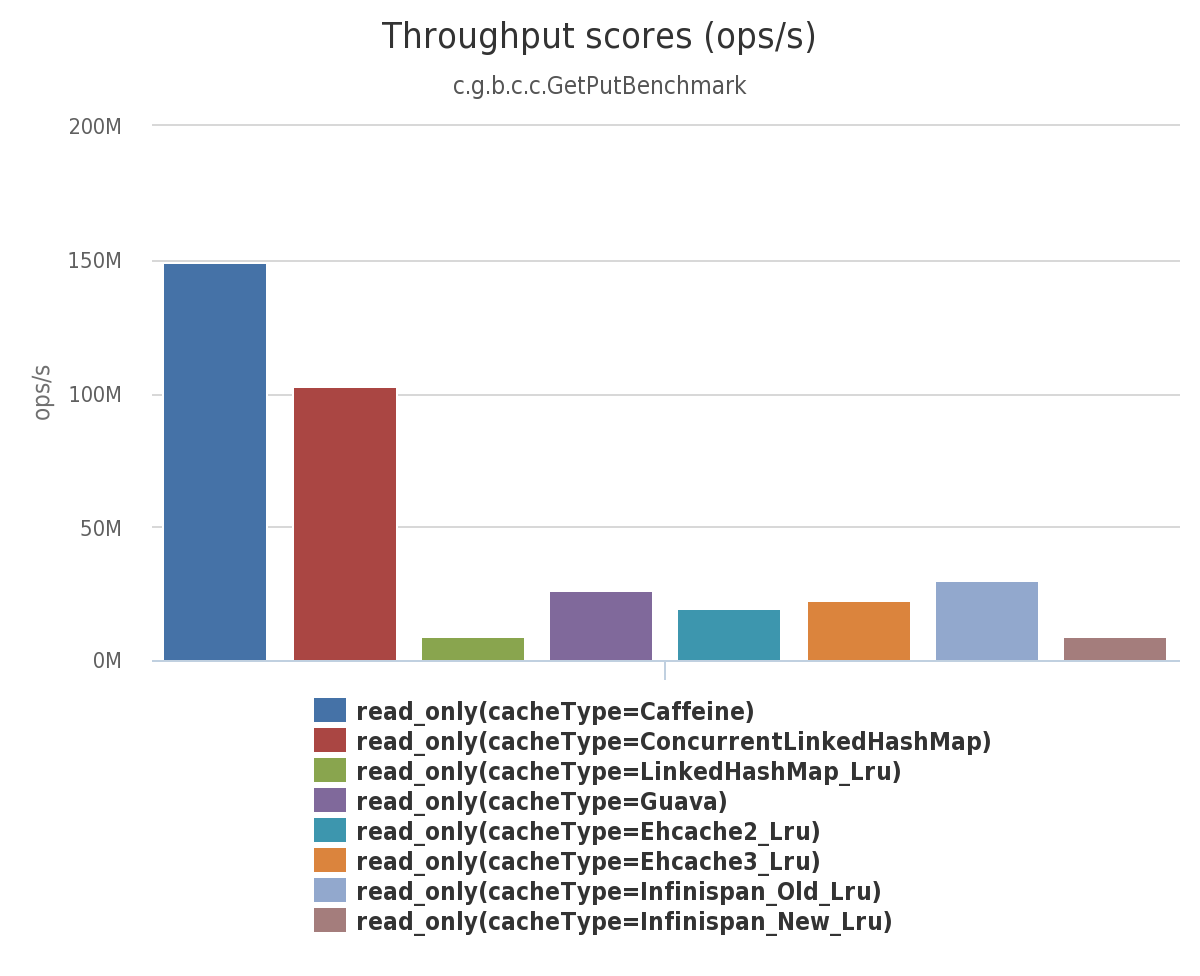{kind=link}
读 (75%) / 写 (25%)
在这个[基准测试][5] 中,对一个配置了最大容量的缓存,6 线程 进行并发读,2 线程进行并发写。
[[ https://raw.githubusercontent.com/ben-manes/caffeine/master/wiki/throughput/readwrite.png | height = 400px ]]
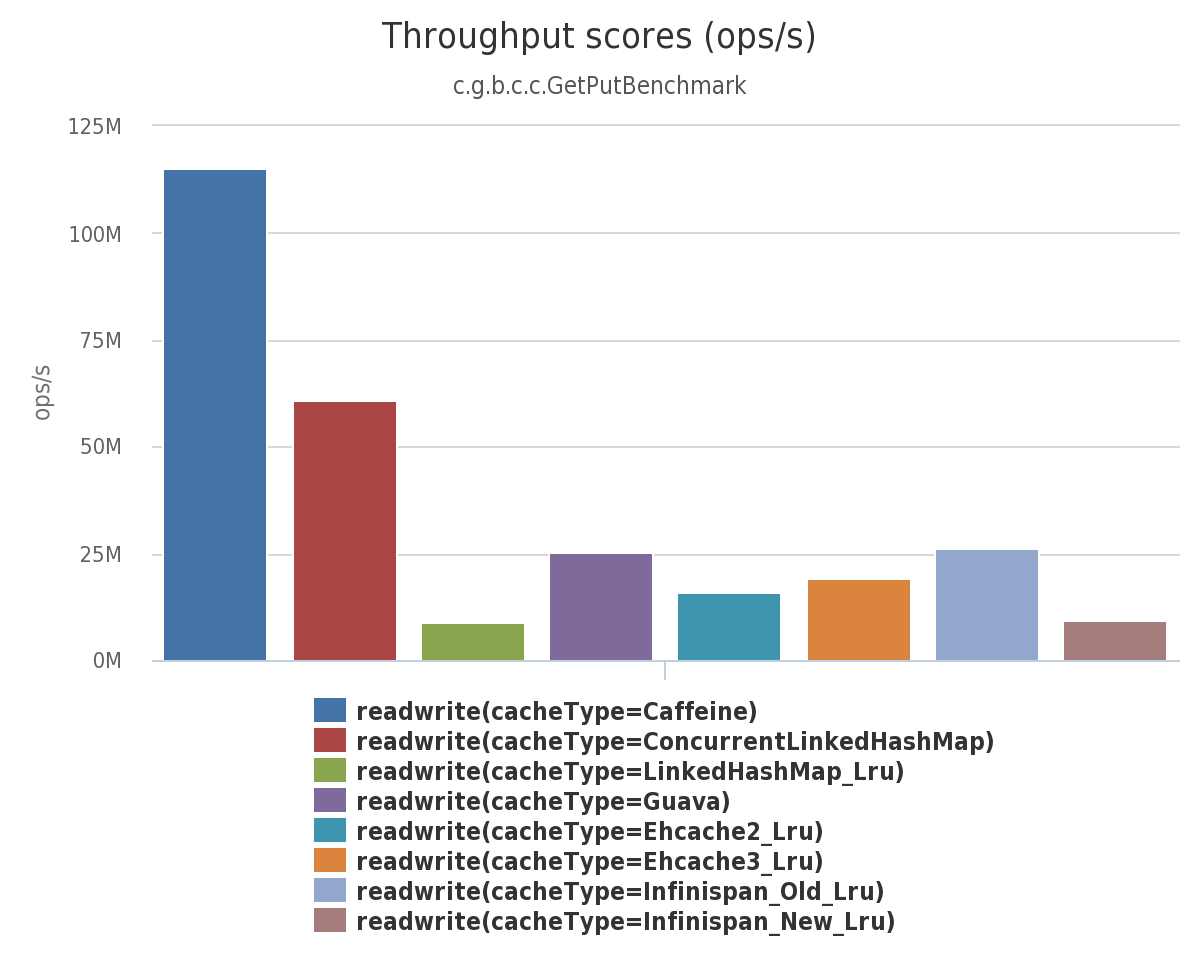{kind=link}
写 (100%)
在这个基准测试 中,8 线程对一个配置了最大容量的缓存进行并发写。
[[ https://raw.githubusercontent.com/ben-manes/caffeine/master/wiki/throughput/write.png | height = 400px ]]
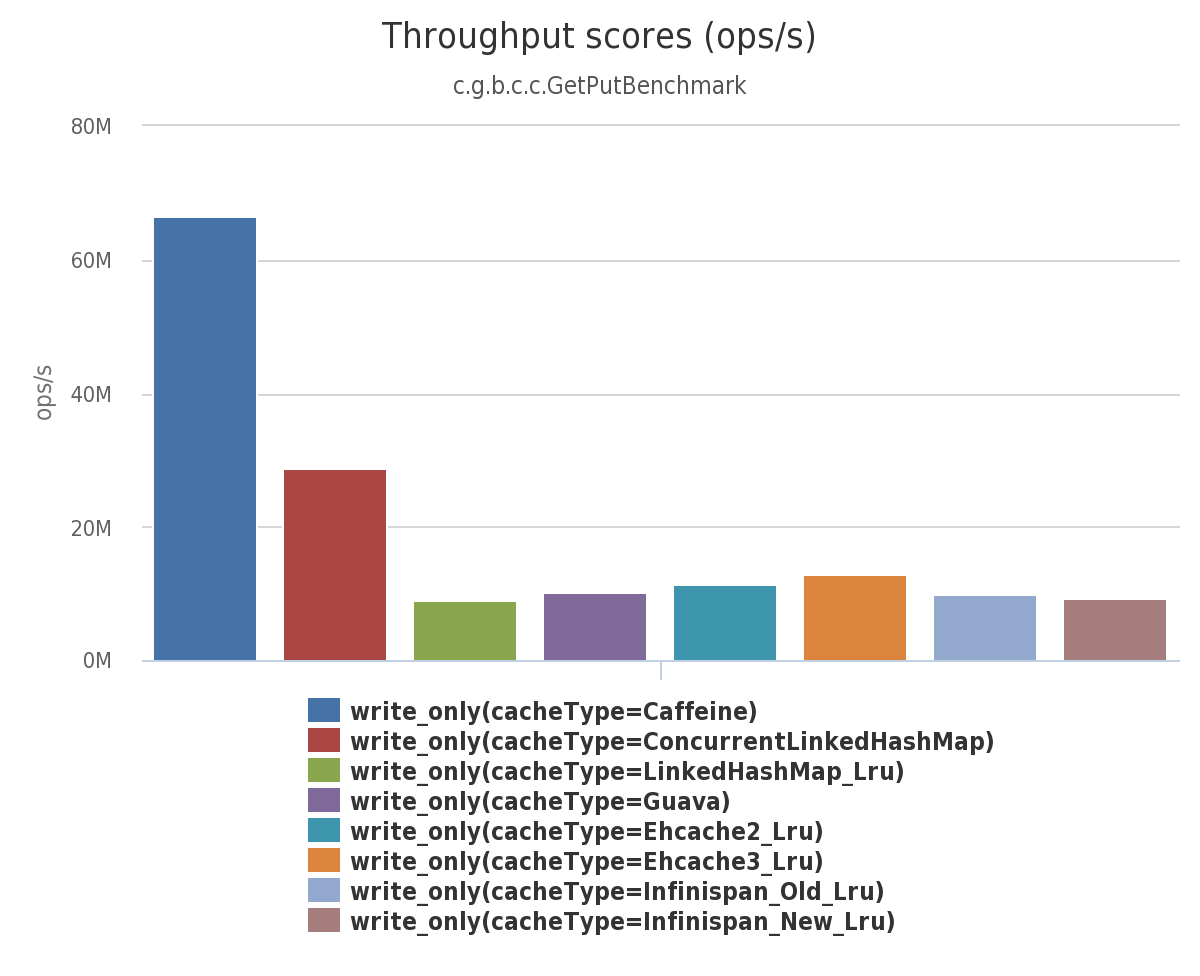{kind=link}
服务器测试环境
基准测试将运行在一台Azure G4之上,是主要云服务商能够在免费试用期内提供的最大实例。这台机器的具体配置是单插槽 Xeon E5-2698B v3 @ 2.00GHz (16 核, 禁用超线程),224 GB,Ubuntu 15.04。
生成计算
Cache
same key
spread
ConcurrentHashMap
29,679,839
65,726,864
Caffeine
1,581,524,763
530,182,873
Guava
25,132,366
114,608,951
读 (100%)
无界
ops/s (8 threads)
ops/s (16 threads)
ConcurrentHashMap (v8)
560,367,163
1,171,389,095
ConcurrentHashMap (v7)
301,331,240
542,304,172
有界
Caffeine
181,703,298
382,355,194
ConcurrentLinkedHashMap
154,771,582
313,892,223
LinkedHashMap_Lru
9,209,065
13,598,576
Guava (default)
12,434,655
10,647,238
Guava (64)
24,533,922
43,101,468
Ehcache2_Lru
11,252,172
20,750,543
Ehcache3_Lru
11,415,248
17,611,169
Infinispan_Old_Lru
29,073,439
49,719,833
Infinispan_New_Lru
4,888,027
4,749,506
读 (75%) / 写 (25%)
无界
ops/s (8 threads)
ops/s (16 threads)
ConcurrentHashMap (v8)
441,965,711
790,602,730
ConcurrentHashMap (v7)
196,215,481
346,479,582
有界
Caffeine
144,193,725
279,440,749
ConcurrentLinkedHashMap
63,968,369
122,342,605
LinkedHashMap_Lru
8,668,785
12,779,625
Guava (default)
11,782,063
11,886,673
Guava (64)
22,782,431
37,332,090
Ehcache2_Lru
9,472,810
8,471,016
Ehcache3_Lru
10,958,697
17,302,523
Infinispan_Old_Lru
22,663,359
37,270,102
Infinispan_New_Lru
4,753,313
4,885,061
写 (100%)
无界
ops/s (8 threads)
ops/s (16 threads)
ConcurrentHashMap (v8)
60,477,550
50,591,346
ConcurrentHashMap (v7)
46,204,091
36,659,485
有界
Caffeine
55,281,751
48,295,360
ConcurrentLinkedHashMap
23,819,597
39,797,969
LinkedHashMap_Lru
10,179,891
10,859,549
Guava (default)
4,764,056
5,446,282
Guava (64)
8,128,024
7,483,986
Ehcache2_Lru
4,205,936
4,697,745
Ehcache3_Lru
10,051,020
13,939,317
Infinispan_Old_Lru
7,538,859
7,332,973
Infinispan_New_Lru
4,797,502
5,086,305
最后更新于
这有帮助吗?